ChefRAG
Assistant culinaire RAG sur ma collection de recettes Umami — tu décris ce que tu veux cuisiner, il cherche dans tes propres recettes.
Contexte
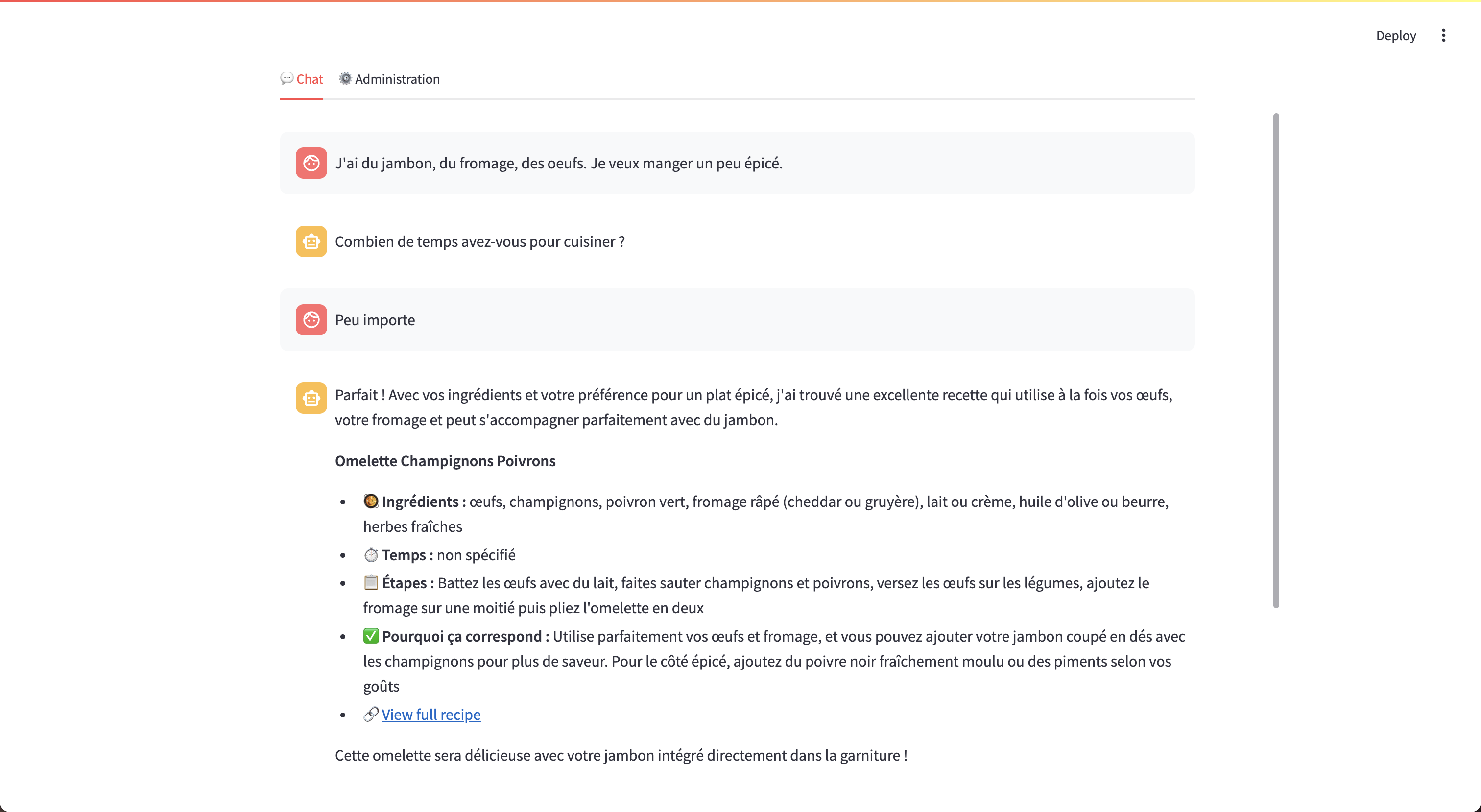
J’utilise Umami au quotidien — c’est mon app de recettes sur iPhone, j’y planifie mes repas, je gère mes listes de courses, et j’y ai accumulé des centaines de recettes au fil des années. Le problème : retrouver une recette précise quand on ne se souvient plus de son titre est frustrant. Et les filtres classiques ne suffisent pas pour répondre à une question comme “j’ai des œufs, du fromage et pas beaucoup de temps”.
L’idée : brancher un LLM directement sur cet export de recettes via RAG (Retrieval-Augmented Generation). Pas de recherche sur internet, pas de recettes génériques — uniquement mes propres recettes, celles que j’ai moi-même sauvegardées.
C’est aussi mon premier projet RAG complet, de l’indexation au déploiement.
Fonctionnalités principales
- Recherche sémantique en langage naturel sur la collection de recettes exportée depuis Umami (format JSON Schema.org)
- Recherche hybride : ChromaDB pour la similarité sémantique, DuckDB pour les filtres structurés (temps de préparation, cuisine, catégorie)
- Intersection des résultats des deux stores avant génération de la réponse
- Questions de clarification dynamiques rendues comme boutons cliquables dans l’UI
- Onglet admin pour déclencher une ré-indexation sans redéployer le container
- Déployé sur Hetzner via Coolify, HTTPS automatique via Let’s Encrypt
Architecture
Le projet s’organise autour de trois couches distinctes :
Indexation (indexer.py) — parsing et validation Pydantic du JSON Umami, nettoyage des données (les ingrédients Umami mélangent vraies lignes et titres de section), indexation en parallèle dans ChromaDB (vecteurs) et DuckDB (métadonnées structurées).
Retrieval hybride — RecipeSearchTool interroge ChromaDB pour la similarité sémantique ; MetadataFilterTool interroge DuckDB pour les contraintes dures (temps, cuisine, catégorie). Les résultats sont intersectés. Si l’intersection est vide, le système bascule sur les résultats sémantiques seuls et l’explique dans la réponse.
Agent (agent.py) — stateless par design, il reçoit l’historique complet à chaque appel. C’est Streamlit via st.session_state qui gère la mémoire de conversation. Claude est branché directement via l’API Anthropic (voir ci-dessous), le contexte RAG est injecté dans le dernier message utilisateur avant envoi.
Requête utilisateur
↓
RecipeSearchTool (ChromaDB) MetadataFilterTool (DuckDB)
↓ ↓
[r1, r2, r3, r4] [r2, r3, r5]
↓
Intersection → Claude → RéponseEmbeddings en local — BAAI/bge-small-en-v1.5 via llama-index-embeddings-huggingface. Le modèle (~130 Mo) est téléchargé au premier démarrage du container et tourne en CPU. Coût d’indexation : zéro.
Décision technique notable : ne pas utiliser llama-index-llms-anthropic
C’est l’ADR le plus instructif du projet. llama-index-llms-anthropic déclare anthropic[bedrock,vertex] comme dépendance, ce qui force les extras AWS et Google Vertex AI — avec des conflits transitifs que pip ne résout pas, quelle que soit la version.
Solution : LlamaIndex gère uniquement le RAG (ChromaDB, embeddings, construction du contexte). Claude est appelé directement :
response = self.anthropic_client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
system=system_prompt,
messages=augmented_messages, # historique + contexte RAG injecté
)Plus de code qu’un wrapper, mais un code qu’on comprend et contrôle entièrement.
Ce que j’ai appris
- Structuration d’un pipeline RAG complet : parsing, validation Pydantic, nettoyage, indexation, retrieval, génération
- Complémentarité ChromaDB (sémantique) + DuckDB (structuré) — deux outils, deux rôles, une intersection
- Avantages d’un agent stateless : tests unitaires simples, pas de state machine à mocker
- Gestion des dépendances Python conflictuelles dans un contexte LLM (packages avec extras transitifs)
- Déploiement Docker multi-container sur Coolify :
chefrag-ui+chefrag-chroma, DuckDB via volume monté
Contraintes et limites connues
RAM sur le VPS. Airflow était prévu initialement pour automatiser la ré-indexation. Retiré du projet : le webserver + scheduler consomme 1,5–2 Go à lui seul. Sur un CX21 à 4 Go avec ChromaDB, le modèle HuggingFace et Streamlit déjà en route, c’était trop juste. Remplacé par un onglet admin dans l’UI — pour un usage solo, déclencher l’indexation manuellement est largement suffisant.
Modèle d’embedding anglais uniquement. bge-small-en-v1.5 est entraîné sur de l’anglais. Mes recettes Umami sont en anglais, donc ça passe. Une extension à des recettes en français nécessiterait un modèle multilingue.
Usage solo uniquement. L’authentification n’est pas implémentée. Le projet est déployé pour un accès personnel, pas pour être ouvert au public.
Installation
git clone https://github.com/jeremy6680/chefrag
cd chefrag
cp .env.example .env
# Renseigne ta clé API Anthropic dans .env
docker compose up -d